 Close
Close

%% [markdown] Parallel Computing Principles in Python
Modern computers are highly parallel systems. Each CPU consists of multiple CPU cores, and within each CPU cores there are vector units that allow the parallel execution of certain operations. In addition, we have GPU accelerators that are highly parallel devices themselves. If we move to larger compute clusters then there is also a level of parallelism between the individual hardware nodes.
In this chapter we will discuss various layers of parallel execution.
As a simple example we consider the following simple code-block.
import numpy as np
n = 1000000
a = np.random.randn(n)
b = np.random.randn(n)
c = np.empty(n, dtype='float64')
for i in range(n):
c[i] = a[i] + b[i]
SIMD Acceleration (vectorisation)¶
Almost all modern CPUs support SIMD (Single-Instruction-Multiple-Data) operations using vector registers. The idea is that a CPU core has internal registers that allow the execution of a command on several arguments within a single CPU cycle.
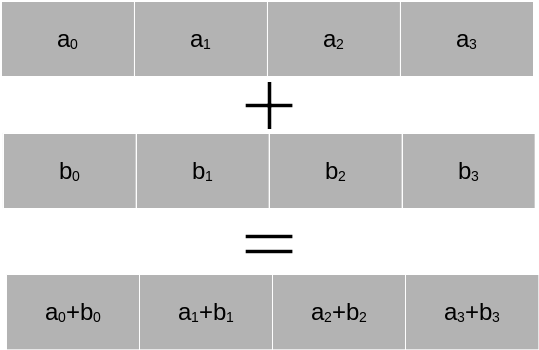
In principle this allows a factor four speed-up. Most modern CPUs from Intel and AMD support AVX2, a set of CPU instructions that allow to operate on vector registers up to 256 bits in length. This is enough space for four double precision numbers or eight single precision numbers. The most modern standard, AVX-512, allows registers twice that size.
SIMD instructions are a very low-level tool, which we cannot use directly in Python. However, several libraries provide functionality that can take advantage of SIMD instructions, in particular:
- Numpy benefits from SIMD if the underlying BLAS library uses SIMD instructions.
- The Numba Just-In-Time compiler for Python code can auto-compile certain for-loops into accelerated SIMD code.
Basics of parallelism¶
SIMD is a very low-level acceleration within a single CPU core. In order to execute code over several cores we need to use a different technique. In order to understand this we first have to clarify what is meant by a process and what is meant by a thread.
A process within a computer is a self-contained unit of code and associated memory that performs a certain task. Many programs consist of a single process. But some programs use multiple process such as Google Chrome, which has a process for each open tab. Processes are strictly separated from each other via the operating system, which schedules the execution of processes. A process is not allowed to directly access data from other processes unless through mechanisms provided by the operating system. Moreover, the operating system decides how processes are scheduled onto CPU cores. If you open a task manager, no matter whether Windows, Linux or Mac, you can see dozens or sometimes even hundreds of processes running at the same time.
A thread is an execution stream within a process. All threads within a process share the memory provided by the process and are freely able to read and manipulate each others data. Performant applications are highly multithreaded to take advantage of the existing CPU cores in a computer.
Shared-memory parallelisation (threading)¶
Conceptually, a threaded application allocates a thread per loop index or group of indices, which execute the computation in parallel. But there is a catch! When Python was first developed it was decided that only one thread at a time would be able to call into the Python interpreter. The consequence is that Python threads are not really executing in parallel since when one thread is calling into the interpreter to execute a Python command the other threads have to wait. This mechanism is called the GIL (Global Interpreter Lock).
There are ongoing efforts, such as the implementation of PEP 703 to make GIL
optional, but Numba allows users to bypass GIL by pass nogil=True to @jit.
Even though threading is not a practical solution for Python code, it is mentioned here because it is widely used to scale code in compiled languages (c, c++ and fortran), which you should consider if you are seriously after performance.
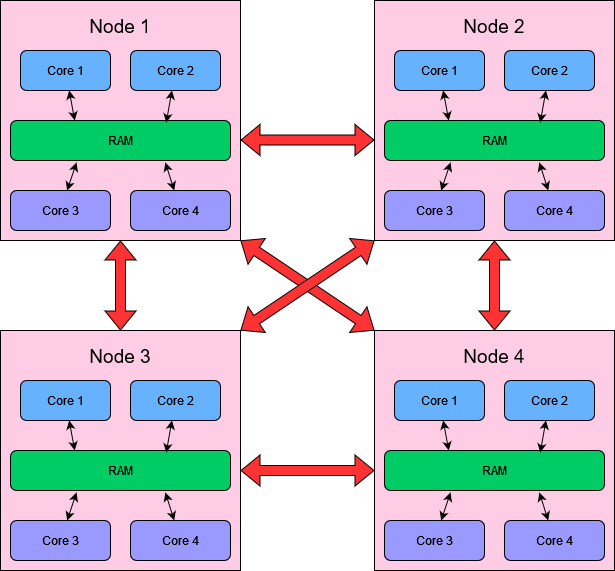
Distributed-memory parallelisation (process-level)¶
Python code can be parallelised across multiple machines in a cluster ("nodes").
The most common way those processes are managed, communicate, and exchange data between them is the Message Passing Interface (MPI). MPI has interfaces for all programming languages used for High Performance Computing. In Python, the mpi4py library provides the needed functionality ("bindings"). We will explore MPI in the following exercise.
There is another Python library, Dask, that can be used to parallelize computation
over multiple nodes. Dask can even parallelize the code marked with @numba.jit(nogil=True)
to multiple threads in a machine, but it does not itself bypass the GIL. You can explore Dask at your own leisure.