Summary and Schedule
The best way to learn how to program is to do something useful, so this introduction to Python is built around a common scientific task: data analysis.
Scenario: Analysing GDP data from countries around the world
We’ve got a set of files containing GDP data from countries around the world, separated into CSV files per continent. Each CSV file contain one row per country and multiple columns per years when the GDP were recorded.
We need to analyse it to see if we understand some global trends across the years.
To do so we would like to:
- Calculate the minimum, maximum and average GDP per continent per year.
- Plot the result to discuss and share with colleagues.
Data Format
The data sets are stored in comma-separated values (CSV) format:
- each row holds information for a single country,
- columns represent years when the GDP were recorded.
The first three rows of our first file look like this, first line contains the header of the file:
country,1952,1957,1962,1967,1972,1977,1982,1987,1992,1997,2002,2007
Algeria,2449.008185,3013.976023,2550.81688,3246.991771,4182.663766,4910.416756,5745.160213,5681.358539,5023.216647,4797.295051,5288.040382,6223.367465
Angola,3520.610273,3827.940465,4269.276742,5522.776375,5473.288005,3008.647355,2756.953672,2430.208311,2627.845685,2277.140884,2773.287312,4797.231267Each number represents the GDP per capita for that particular country on the given year.
For example, value “3008.647355” at row 3 column 7 of the data set above means that Angola had a GDP per capita of approximately $3,008.65 in 1977.
In order to analyze this data and report to our colleagues, we’ll have to learn a little bit about programming.
Prerequisites
You need to understand the concepts of files and directories and how to start a Python interpreter before tackling this lesson. This lesson sometimes references Jupyter Lab although you can use any Python interpreter mentioned in the [Setup][lesson-setup].
The commands in this lesson pertain to any officially supported Python version, currently Python 3.7+. Newer versions usually have better error printouts, so using newer Python versions is recommend if possible.
Getting Started
To get started, follow the directions on the “[Setup][lesson-setup]” page to download data and install a Python interpreter.
| Setup Instructions | Download files required for the lesson | |
| Duration: 00h 00m | 1. Python Fundamentals |
What basic data types can I work with in Python? How can I create a new variable in Python? How do I use a function? Can I change the value associated with a variable after I create it? |
| Duration: 00h 30m | 2. Reading Tabular Data into DataFrames |
How can I read tabular data in Python? How can I get information about the type of data I have read in? |
| Duration: 01h 30m | 3. Visualizing Tabular Data |
How can I visualize tabular data in Python? How can I group several plots together? |
| Duration: 02h 30m | 4. Storing Multiple Values in Lists | How can I store many values together? |
| Duration: 03h 15m | 5. Repeating Actions with Loops | How can I do the same operations on many different values? |
| Duration: 03h 45m | 6. Analyzing Data from Multiple Files | How can I do the same operations on many different files? |
| Duration: 04h 05m | 7. Making Choices | How can my programs do different things based on data values? |
| Duration: 04h 35m | 8. Creating Functions |
How can I define new functions? What’s the difference between defining and calling a function? What happens when I call a function? |
| Duration: 05h 05m | 9. Errors and Exceptions |
How does Python report errors? How can I handle errors in Python programs? |
| Duration: 05h 35m | 10. Defensive Programming | How can I make my programs more reliable? |
| Duration: 06h 15m | 11. Debugging | How can I debug my program? |
| Duration: 07h 05m | 12. Command-Line Programs | How can I write Python programs that will work like Unix command-line tools? |
| Duration: 07h 35m | Finish |
The actual schedule may vary slightly depending on the topics and exercises chosen by the instructor.
Overview
This lesson is designed to be run on a personal computer. All of the software and data used in this lesson are freely available online, and instructions on how to obtain them are provided below.
Install Python
In this lesson, we will be using Python 3 with some of its most popular scientific libraries. Although one can install a plain-vanilla Python and all required libraries by hand, we recommend installing Anaconda, a Python distribution that comes with everything we need for the lesson. Detailed installation instructions for various operating systems can be found on The Carpentries template website for workshops and in Anaconda documentation.
Obtain lesson materials
- Download python-novice-gapminder-data.zip and python-novice-gapminder-code.zip.
- Create a folder called
swc-pythonon your Desktop. - Move downloaded files to
swc-python. - Unzip the files.
You should see two folders called data and
code in the swc-python directory on your
Desktop.
Launch Python interface
To start working with Python, we need to launch a program that will interpret and execute our Python commands. Below we list several options. If you don’t have a preference, proceed with the top option in the list that is available on your machine. Otherwise, you may use any interface you like.
Option A: Jupyter Notebook
A Jupyter Notebook provides a browser-based interface for working with Python. If you installed Anaconda, you can launch a notebook in two ways:
- Launch Anaconda Navigator. It might ask you if you’d like to send
anonymized usage information to Anaconda developers:
 Make your choice and click “Ok,
and don’t show again” button.
Make your choice and click “Ok,
and don’t show again” button. - Find the “JupyterLab” tab and click on the “Launch” button:
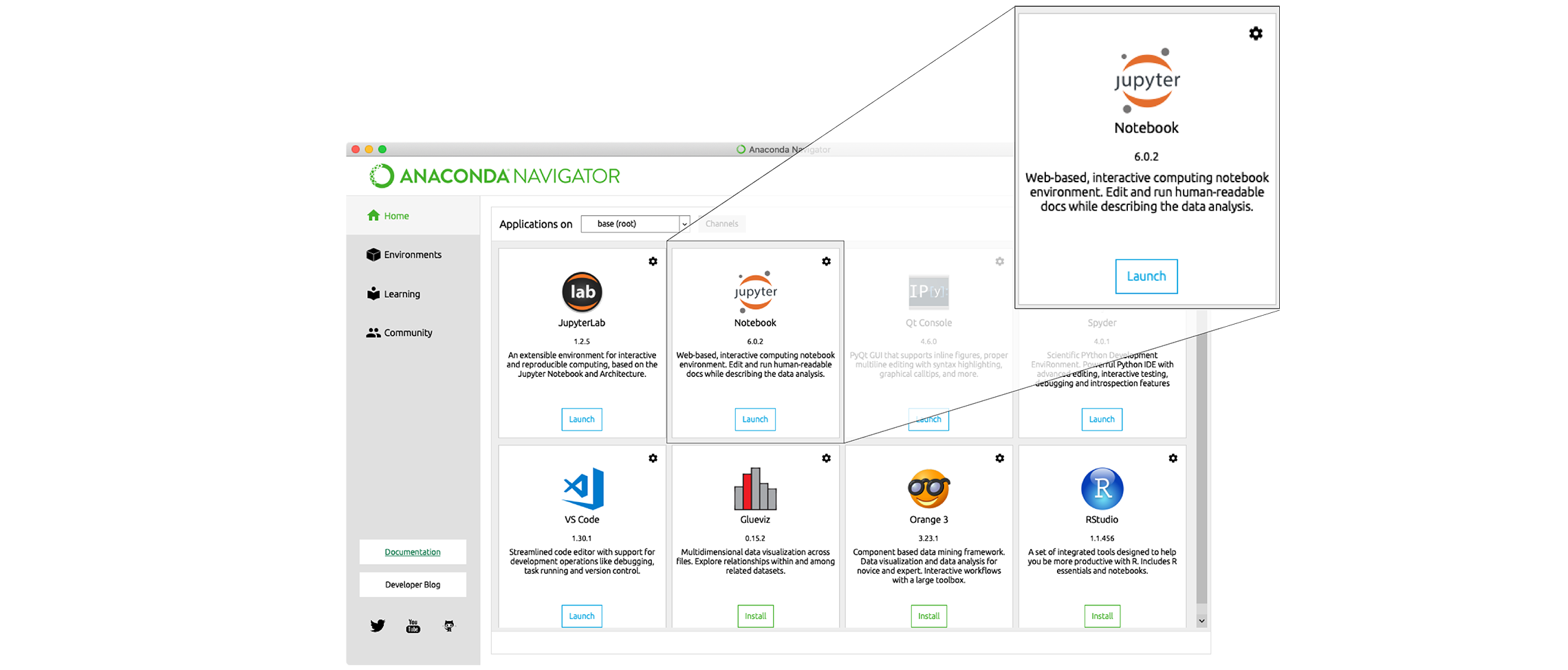 Anaconda will open a new browser window or tab with a Notebook Dashboard
showing you the contents of your Home (or User) folder.
Anaconda will open a new browser window or tab with a Notebook Dashboard
showing you the contents of your Home (or User) folder. - Navigate to the
datadirectory by clicking on the directory names leading to it:Desktop,swc-python, thendata: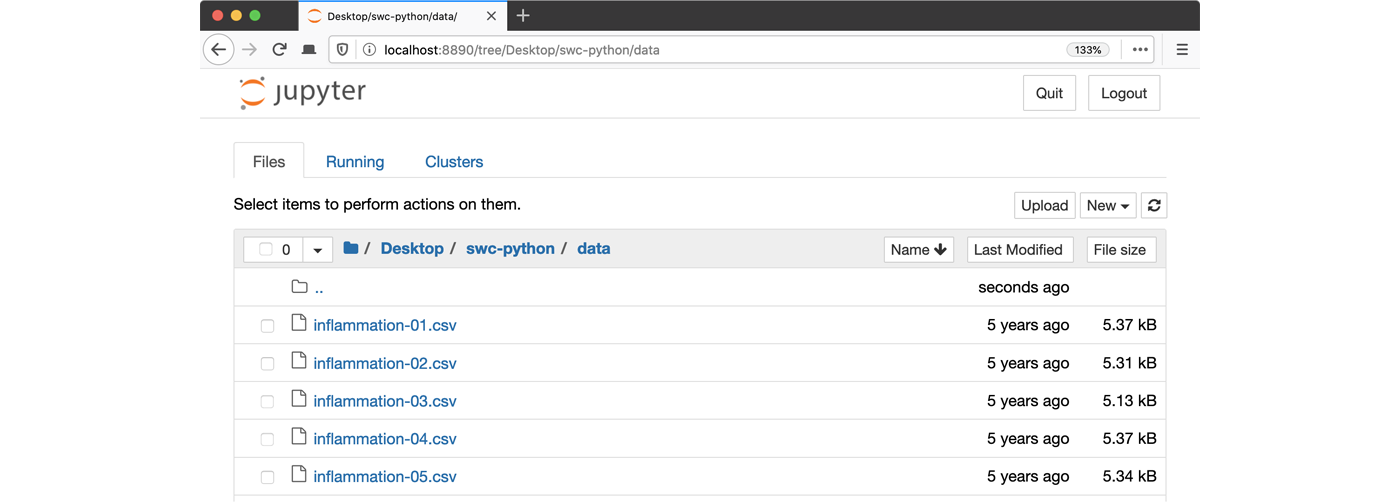
- Launch the notebook by clicking on the “New” button and then
selecting “Python 3”:
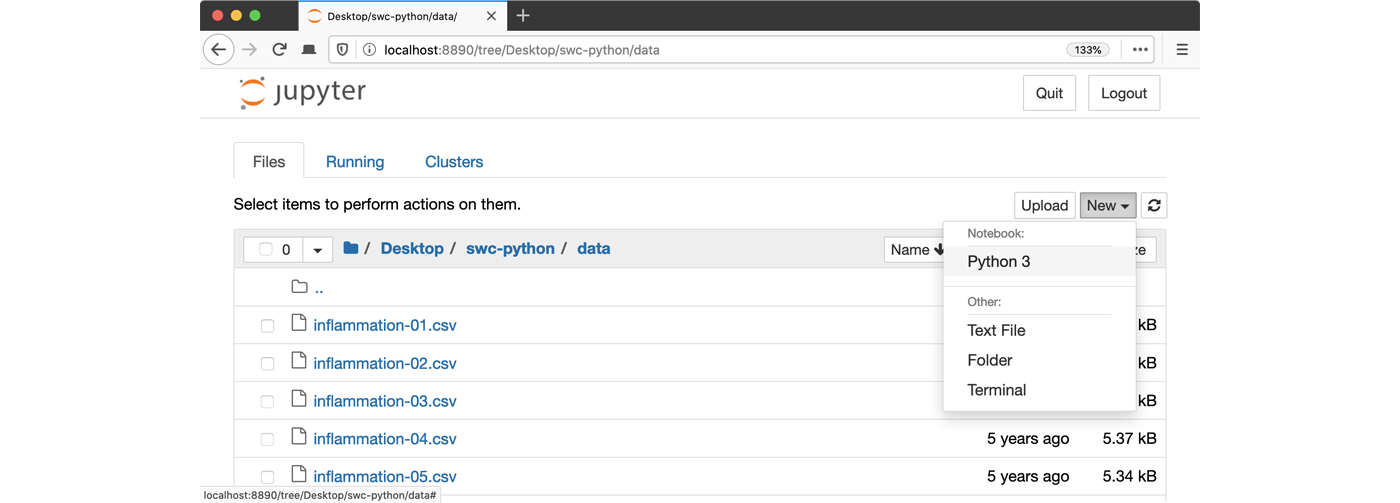
1. Navigate to the data directory:
If you’re using a Unix shell application, such as Terminal app in macOS, Console or Terminal in Linux, or Git Bash on Windows, execute the following command:
On Windows, you can use its native Command Prompt program. The
easiest way to start it up is pressing Windows Logo
Key+R, entering cmd, and hitting
Return. In the Command Prompt, use the following command to
navigate to the data folder:
cd /D %userprofile%\Desktop\swc-python\data2. Start Jupyter server
python -m notebook3. Launch the notebook by clicking on the “New” button on the right
and selecting “Python 3” from the drop-down menu: 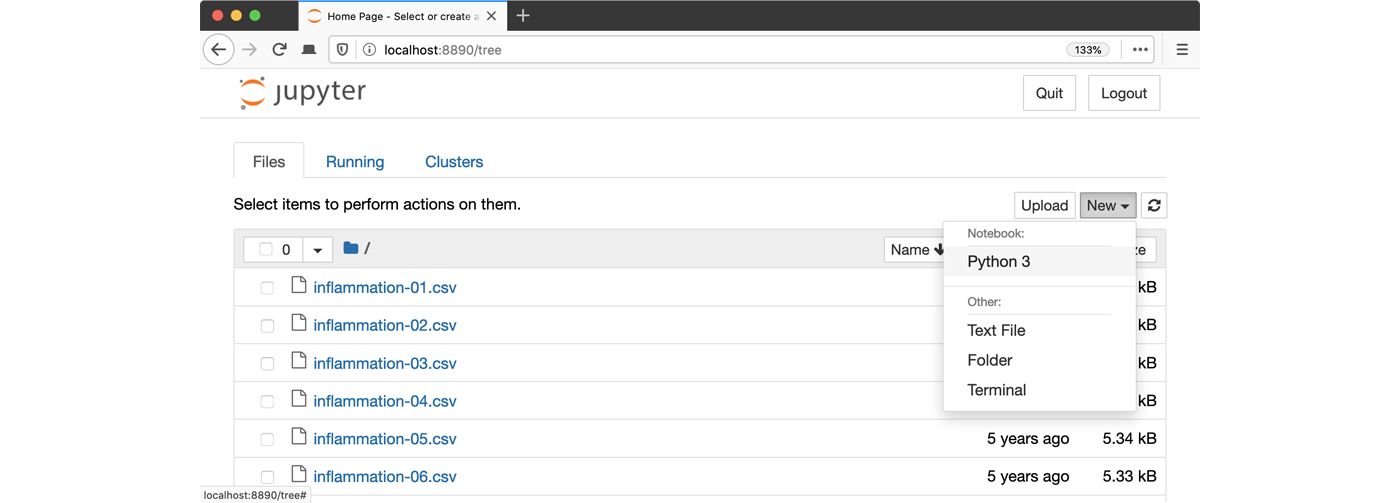
Option B: IPython interpreter
IPython is an alternative solution situated somewhere in between the plain-vanilla Python interpreter and Jupyter Notebook. It provides an interactive command-line based interpreter with various convenience features and commands. You should have IPython on your system if you installed Anaconda.
To start using IPython, execute:
ipython
Option C: plain-vanilla Python interpreter
To launch a plain-vanilla Python interpreter, execute:
pythonIf you are using Git Bash on
Windows, you have to call Python via
winpty:
winpty python