Creating Functions
Last updated on 2024-02-23 | Edit this page
Overview
Questions
- How can I define new functions?
- What’s the difference between defining and calling a function?
- What happens when I call a function?
Objectives
- Define a function that takes parameters.
- Return a value from a function.
- Test and debug a function.
- Set default values for function parameters.
- Explain why we should divide programs into small, single-purpose functions.
Prerequisite
In this lesson we are going to be using the data in the
penguin_data.csv file, which is a subset of the freely
available dataset palmerpenguins.
This dataset contains the species, culmen length, culmen depth, flipper
length and mass of 343 penguins observed on the Palmer archipelago,
Antarctica.

If you are starting a new notebook, you’ll need to
import Pandas and load this data into a variable, which we
will call penguins. We have assigned each penguin a name,
which we will use as the row labels (and pass to the
index_col parameter).
We will also be making plots, so we’ll need to import
matplotlib.pyplot like we did in lesson 3. And finally, we
also need the mathematical constant \(\pi\) (pi), which we can
import from the math library that comes with
Python. For this we will be using from to only import a
single “thing” (pi in this case).
PYTHON
from math import pi
import pandas as pd
import matplotlib.pyplot as plt
penguins = pd.read_csv('data/penguin_data.csv', index_col='name')
print("Pi is:", pi)
print("Our dataset looks like:")
print(penguins.head(5))OUTPUT
Pi is: 3.141592653589793
Our dataset looks like:
id species culmen depth (mm) culmen length (mm) \
name
lyndale N34A2 Gentoo 16.3 51.5
drexel N32A1 Adelie 16.6 35.9
delaware N56A2 Gentoo 16.0 48.6
phillips N20A2 Gentoo 16.8 49.8
south shore N65A2 Chinstrap 18.8 51.0
flipper length (mm) mass (kg)
name
lyndale 230.0 5.50
drexel 190.0 3.05
delaware 230.0 5.80
phillips 230.0 5.70
south shore 203.0 4.10Having recently returned from a research trip to Antarctica, a researcher has hypothesised that penguin species with larger bills are able to consume more food than those with smaller bills. The trouble is, the data that’s been collected doesn’t record the information they want directly - we will need to infer this information from the data that has been recorded.
We’re going to have to do a lot of calculations with the data to help justify this researcher’s claims. It would be helpful if we didn’t have to manually type out these calculations every time we want to perform them. This is where functions come in: given some inputs, they define a sequence of steps which produce an output.
Functions are like recipes
Python views functions in the same ways as humans might view recipes when cooking. Given some ingredients (the inputs), you follow the recipe (the instructions/steps), to produce a meal (the output). You might decide to switch out the vegetables you’re using, or switch chips for something like sweet potato fried, and so you get a different meal even if the steps you take to make the meal are the same.
You only have to look in one place for the recipe to know what you’re doing. Similarly, functions let us write one set of instructions that can be run multiple times in our code. This also helps if we find a bug in our instructions - we only have to change the instructions in one place (the function) rather than all over our notebook!
The researcher informs us that we can treat the bill of a penguin as a cylinder, with the “depth” being the diameter of the cylinder and the “length” the height. The volume of a cylinder is given by \[ \text{cylinder volume} = \text{cylinder height} \times \pi \left(\text{cylinder radius} \right)^2. \] This is not a simple calculation to write out every time we need to do it, and we will most likely want to do this calculation a lot in our analysis! So we can define a function that can perform this calculation for us.

A function always start with “def”, followed by the name of the
function (cylinder_volume). After the name, we put in
brackets the parameters (or arguments) that the function takes
(height, radius). The body concludes with a
return keyword that tells Python the value that this
function should provide as the output. In this function we’re also using
**, that’s the operator can be used to raise a number to a
power.
When we call the function, the values we pass to it are assigned to those variables so that we can use them inside the function. Inside the function, we use a return statement to send a result back to whoever asked for it. Let’s try running our function:
The volume of a cylinder with radius 1 and height 1, should be
1 * pi * 1 ** 2 = pi
This command should call our function, using “1” as the input for
height, and “1” as the input for radius, and
return the function value. In fact, calling our own function is no
different from calling any other function:
PYTHON
print('cylinder with no height has volume:', cylinder_volume(0, 1))
print('cylinder with height 1 and radius 1 has volume:', cylinder_volume(1, 1))OUTPUT
cylinder with no height has volume: 0.0
cylinder with height 1 and radius 1 has volume: 3.141592653589793We’ve successfully called the function that we defined, and we have access to the value that we returned.
Composing Functions
Now that we have a function to calculate the volume of a cylinder, we can start to estimate the bill sizes of our penguins. From the researcher’s explanation, the bill size of a penguin can be worked out as: \[ \text{bill size} = \text{culmen height} \times \pi \left(\frac{\text{culmen depth}}{2} \right)^2, \] since the culmen depth is the cylinder’s diameter — which is double the radius.
So how can we write out a function to estimate the bill size from the
culmen length and culmen depth? We could write out the formula above,
but we don’t need to. Instead, we can compose our
cylinder_volume function with a statement that divides the
diameter by 2 to obtain the radius. We use it then to compute the bill
size of the penguin ‘phillips’.
PYTHON
def penguin_bill_size(culmen_length, culmen_depth):
culmen_radius = culmen_depth / 2
culmen_size = cylinder_volume(culmen_length, culmen_radius)
return culmen_size
phillips_length = penguins.loc['phillips','culmen length (mm)']
phillips_depth = penguins.loc['phillips','culmen depth (mm)']
print('Penguin phillips has bill size', penguin_bill_size(phillips_length, phillips_depth), "mm^3")OUTPUT
Penguin phillips has bill size 11039.204726337332 mm^3This is our first taste of how larger programs are built: we define basic operations, then combine them in ever-larger chunks to get the effect we want. Real-life functions will usually be larger than the ones shown here — typically half a dozen to a few dozen lines — but they shouldn’t ever be much longer than that, or the next person who reads it won’t be able to understand what’s going on.
Variable Scope
In composing our cylinder_volume function, we created
variables inside of those functions —
culmen_radius and culmen_size inside
penguin_bill_size, and volume within
cylinder_radius. We refer to these variables as local variables because they no
longer exist once the function is done executing. If we try to access
their values outside of the function, we will encounter an error:
ERROR
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_8392/2249064020.py in <module>
----> 1 print('The culmen_radius was:', culmen_size)
NameError: name 'culmen_size' is not definedIf you want to reuse the bill size you’ve calculated, you can store the result of the function call in a variable:
OUTPUT
bill_size was: 3.141592653589793The variable bill_size, being defined outside any
function, is said to be global.
Inside a function, one can read the value of such global variables.
For example, our cylinder_volume function is able to read
the value of pi, even though we didn’t actually assign
pi within the function!
PYTHON
def cylinder_volume(height, radius):
print("This function knows the value of pi is", pi)
volume = height * pi * radius ** 2
return volume
volume = cylinder_volume(0, 0)
print("Volume was:", volume)OUTPUT
This function knows the value of pi is 3.141592653589793
Volume was: 0.0Operating on dataframe columns
Our penguin_bill_size function performs well when we
give it two individual numbers for the culmen length and depth. But our
dataframe has 343 penguins in it — we don’t want to call the function
343 times if we can avoid it! Fortunately for us, dataframes are clever
enough to allow us to “operate along columns”. If we want to do the
same calculation with all the values in two dataframe columns,
we can just give our function the dataframe columns containing
all the culmen lengths and culmen depths:
PYTHON
bill_sizes = penguin_bill_size(penguins['culmen length (mm)'], penguins['culmen depth (mm)'])
print(bill_sizes)This is an example of vectorisation; Python can perform the
same command across a set of data much faster than it would if we called
the penguin_bill_size 343 times on the individual culmen
lengths and depths!
Tidying up
Now that we know how to wrap bits of code up in functions, we can
make our analysis of the size of penguin bills easier to read and reuse.
The researcher was interested in whether different penguin species have
different bill sizes, and a natural way to test this is to produce a box
plot for each of the species we have data on. First, let’s make a
visualise_bill_sizes function that generates a box plot for
a single species of penguin:
PYTHON
def visualise_bill_sizes(penguin_data, species_name):
if species_name in penguin_data['species'].values:
# We have some data on that species of penguin!
this_species = penguins.loc[penguins['species'] == species_name]
# Now let's work out the bill sizes of these penguins
bill_sizes = penguin_bill_size(this_species['culmen length (mm)'], this_species['culmen depth (mm)'])
# Now let's make a plot of these bill sizes
fig = plt.figure(figsize=(10., 3.))
bill_sizes.plot.box(vert=False)
plt.title(species_name + " penguins")
plt.xlabel("Bill sizes (mm^3)")
plt.show()
else:
print("There is no data on penguin species:", species_name)This function checks first whether the species name requested exists on the dataframe. If the species exists, then it proceeds to generate the plot, otherwise it prints a message informing that the species is not in the dataframe.
Wait! Didn’t we forget to specify what this functions should return?
Well, we didn’t. In Python, functions are not required to include a
return statement and can be used for the sole purpose of
grouping together pieces of code that conceptually do one thing. In such
cases, function names usually describe what they do, e.g.
visualise_bill_sizes.
Notice that rather than jumbling this code together in one giant
for loop, we can now read and reuse both ideas separately.
We can produce a box plot for each species of penguin using a
for loop, and by putting our function inside it!
PYTHON
penguins = pd.read_csv('data/penguin_data.csv', index_col='name')
unique_species = penguins['species'].unique
for species in unique_species:
visualise_bill_sizes(penguins, species)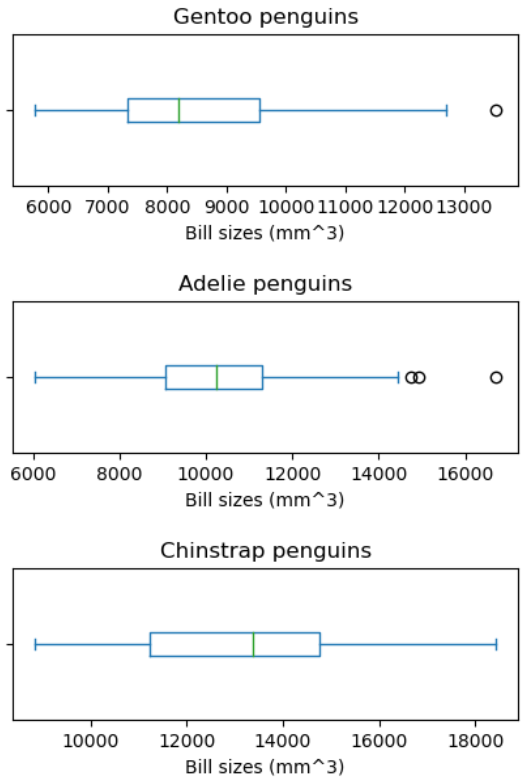
By giving our functions human-readable names, we can more easily read
and understand what is happening in the for loop. Even
better, if at some later date we want to use either of those pieces of
code again, we can do so in a single line.
Combining Strings
“Adding” two strings produces their concatenation:
'a' + 'b' is 'ab'. Write a function called
fence that takes two parameters called
original and wrapper and returns a new string
that has the wrapper character at the beginning and end of the original.
A call to your function should look like this:
OUTPUT
*name*Return versus print
Note that return and print are not
interchangeable. print is a Python function that
prints data to the screen. It enables us, users, see
the data. return statement, on the other hand, makes data
visible to the program. Let’s have a look at the following function:
Question: What will we see if we execute the following commands?
Python will first execute the function add with
a = 7 and b = 3, and, therefore, print
10. However, because function add does not
have a line that starts with return (no return
“statement”), it will, by default, return nothing which, in Python
world, is called None. Therefore, A will be
assigned to None and the last line (print(A))
will print None. As a result, we will see:
OUTPUT
10
NoneRescaling an Array
Our researcher has decided that it would be much clearer if all the
bill sizes were rescaled so that the corresponding values in the
'species' column lie in the range 0.0 to 1.0. Write a new
function rescaled_bill_sizes that: - Takes a dataframe of
penguins as it’s input. - Calculates the bill sizes of all the penguins
in the dataframe, then rescales the values to be in this range. -
Returns the rescaled bill sizes as the output.
Hint: If L and H are the lowest and highest
values of the original bill sizes, then the replacement for a bill size
size should be (size-L) / (H-L).
OUTPUT
259.81666666666666
278.15
273.15
0k is 0 because the k inside the function
f2k doesn’t know about the k defined outside
the function. When the f2k function is called, it creates a
local variable
k. The function does not return any values and does not
alter k outside of its local copy. Therefore the original
value of k remains unchanged. Beware that a local
k is created because f2k internal statements
affect a new value to it. If k was only
read, it would simply retrieve the global k
value.
Variables Inside and Outside Functions (continued)
Do you recognise what is this function doing?
It converts temperature between Fahrenheit and Kelvin degrees. Probably, it would have been easier to understand if written in this way:
PYTHON
def fahr_to_kelvin(temp_f):
temp_celsius = (temp_f - 32) * (5/9)
temp_kelvin = temp_celsius + 273.15
return temp_kelvinNaming functions and variables in a readable helps the next person who comes to read your code. That next person could be your future-self!
Producing a scatter plot
Write a function plot_bill_size_vs_flipper that: - Takes
the penguin data and the name of a species as its arguments - Produces a
scatter plot for that species; with the flipper size on the x-axis and
bill size on the y-axis - Shows this plot on the screen.
Hint: plt.scatter(x_data, y_data) produces a scatter
plot.
PYTHON
def plot_bill_size_vs_flipper(penguin_data, species_name):
if species_name in penguin_data['species'].values:
this_species = penguins.loc[penguins['species'] == species_name]
bill_sizes = penguin_bill_size(this_species['culmen length (mm)'], this_species['culmen depth (mm)'])
fig = plt.figure(figsize=(5., 5.))
plt.scatter(this_species['flipper length (mm)'], bill_sizes)
plt.title(species_name + " penguins")
plt.xlabel("Flipper length (mm)")
plt.ylabel("Bill sizes (mm^3)")
plt.show()
else:
print("There is no data on penguin species:", species_name)Tidying up
Now that we know how to wrap bits of code up in functions, we can
make our GDP analysis easier to read and easier to reuse. First, let’s
make a visualize function that generates our plots:
PYTHON
def visualize(filename):
continent = filename.split('_')[-1][:-4].capitalize()
data_gdp = pd.read_csv(filename, index_col='country')
fig = plt.figure(figsize=(18.0, 3.0))
axes_1 = fig.add_subplot(1, 3, 1)
axes_2 = fig.add_subplot(1, 3, 2)
axes_3 = fig.add_subplot(1, 3, 3)
axes_1.set_title('Min')
axes_1.set_ylabel('GDP/capita')
axes_1.plot(data_gdp.min(axis='rows'))
axes_2.set_title('Max')
axes_2.plot(data_gdp.max(axis='rows'))
axes_3.set_title('Average')
axes_3.plot(data_gdp.mean(axis='rows'))
fig.suptitle('GDP/capita statistics for countries in ' + continent)
fig.tight_layout()
plt.show()and another function called detect_problems that checks
for those systematics we noticed:
PYTHON
def detect_problems(filename):
data_gdp = pd.read_csv(filename, index_col='country')
min_data = data_gdp.min(axis='rows')
min_min_data = min_data.min()
max_min_data = min_data.max()
if min_min_data == 0 and max_min_data == 0:
print('Suspicious looking minima!')
elif round(data.mean(axis='rows').min()) == round(data.mean(axis='rows').max()):
print('Average is flat!')
else:
print('Seems OK!')Notice that rather than jumbling this code together in one giant
for loop, we can now read and reuse both ideas separately.
We can reproduce the previous analysis with a much simpler
for loop:
PYTHON
filenames = sorted(glob.glob('data/gapminder_*.csv'))
for filename in filenames[:3]:
print(filename)
visualize(filename)
detect_problems(filename)By giving our functions human-readable names, we can more easily read
and understand what is happening in the for loop. Even
better, if at some later date we want to use either of those pieces of
code again, we can do so in a single line.
Testing and Documenting
Once we start putting things in functions so that we can re-use them, we need to start testing that those functions are working correctly. To see how to do this, let’s write a function to convert values between USD to GBP:
We could test this on our actual data, but since we don’t know what the values ought to be, it will be hard to tell if the result was correct. Instead, let’s input a value manually, 1 USD, and 0.8 USD-GBP rate:
OUTPUT
0.8That looks right, so let’s try usd_to_gbp on our real
data:
PYTHON
data_gdp = pd.read_csv('data/gapminder_gdp_oceania.csv', index_col='country')
print('in USD')
print(data_gdp.loc[:, 1952:1962])
print('in GBP')
print(usd_to_gbp(data_gdp.loc[:, 1952:1962], 0.8))OUTPUT
in USD
1952 1957 1962
country
Australia 10039.59564 10949.64959 12217.22686
New Zealand 10556.57566 12247.39532 13175.67800
in GBP
1952 1957 1962
country
Australia 8031.676512 8759.719672 9773.781488
New Zealand 8445.260528 9797.916256 10540.542400We have one more task to do first, though: we should write some documentation for our function to remind ourselves later what it’s for and how to use it.
The usual way to put documentation in software is to add comments like this:
PYTHON
# usd_to_gbp(data, usd_gbp_rate):
# return the input data converted to GBP
def usd_to_gbp(data, usd_gbp_rate):
return (data * usd_gbp_rate)There’s a better way, though. If the first thing in a function is a string that isn’t assigned to a variable, that string is attached to the function as its documentation:
PYTHON
def usd_to_gbp(data, usd_gbp_rate):
"""Return the input data converted to GBP.
"""
return (data * usd_gbp_rate)This is better because we can now ask Python’s built-in help system to show us the documentation for the function:
OUTPUT
Help on function usd_to_gbp in module __main__:
usd_to_gbp(data, usd_gbp_rate):
Return the input data converted to GBP.A string like this is called a docstring. We don’t need to use triple quotes when we write one, but if we do, we can break the string across multiple lines:
PYTHON
def usd_to_gbp(data, usd_gbp_rate):
"""Return the input data converted to GBP.
Examples
--------
>>> usd_to_gbp(10, 0.80)
8.
"""
return (data * usd_gbp_rate)
help(usd_to_gbp)OUTPUT
Help on function usd_to_gbp in module __main__:
usd_to_gbp(data, usd_gbp_rate):
Return the input data converted to GBP.
Examples
--------
>>> usd_to_gbp(10, 0.80)
8.Defining Defaults
We have passed parameters to functions in two ways: directly, as in
type(data), and by name, as in
pd.read_csv(filename, index_col='country'). but we still
need to say index_col=:
ERROR
Traceback (most recent call last):
ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
oceania = pd.read_csv('data/gapminder_gdp_oceania.csv', 'country')To understand what’s going on, and make our own functions easier to
use, let’s re-define our usd_to_gbp function like this:
PYTHON
def usd_to_gbp(data, usd_gbp_rate=0.8):
"""Return the input data converted to GBP (usd to gbp rate as 0.8 by default).
Examples
--------
>>> usd_to_gbp(10)
8.
"""
return (data * usd_gbp_rate)The key change is that the second parameter is now written
usd_gbp_rate=0.8 instead of just usd_gbp_rate.
If we call the function with two arguments, it works as it did
before:
OUTPUT
0.3But we can also now call it with just one parameter, in which case
usd_gbp_rate is automatically assigned the default value of 0.8.
This is handy: if we usually want a function to work one way, but occasionally need it to do something else, we can allow people to pass a parameter when they need to but provide a default to make the normal case easier. The example below shows how Python matches values to parameters:
PYTHON
def display(a=1, b=2, c=3):
print('a:', a, 'b:', b, 'c:', c)
print('no parameters:')
display()
print('one parameter:')
display(55)
print('two parameters:')
display(55, 66)OUTPUT
no parameters:
a: 1 b: 2 c: 3
one parameter:
a: 55 b: 2 c: 3
two parameters:
a: 55 b: 66 c: 3As this example shows, parameters are matched up from left to right, and any that haven’t been given a value explicitly get their default value. We can override this behavior by naming the value as we pass it in:
OUTPUT
only setting the value of c
a: 1 b: 2 c: 77With that in hand, let’s look at the help for
pd.read_csv:
OUTPUT
Help on function read_csv in module pandas.io.parsers.readers:
read_csv(filepath_or_buffer: 'FilePath | ReadCsvBuffer[bytes] | ReadCsvBuffer[str]', *, sep: 'str | None | lib.NoDefault' = <no_default>, ...
Read a comma-separated values (csv) file into DataFrame.
Also supports optionally iterating or breaking of the file
into chunks.
Additional help can be found in the online docs for
`IO Tools <https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html>`_.
Parameters
----------
...There’s a lot of information here, but the most important part is the first couple of lines:
OUTPUT
read_csv(filepath_or_buffer: 'FilePath | ReadCsvBuffer[bytes] | ReadCsvBuffer[str]', *, sep: 'str | None | lib.NoDefault' = <no_default>, ...This tells us that read_csv has one parameter called
filepath_or_buffer that doesn’t have a default value, and
many others that do. If we call the function like this:
then the filename is assigned to filepath_or_buffer
(which is what we want), but the index column string
'country' is assigned to sep rather than
index_col, because sep is the second parameter
in the list. However 'country' isn’t a known delimiter so
our code produced an error message when we tried to run it. When we call
pd.read_csv we don’t have to provide
filepath_or_buffer= for the filename because it’s the first
item in the list, but if we want the 'country' to be
assigned to the variable index_col, we do have to
provide index_col= for the second parameter since
ndex_col is not the second parameter in the list.
Mixing Default and Non-Default Parameters
Given the following code:
PYTHON
def numbers(one, two=2, three, four=4):
n = str(one) + str(two) + str(three) + str(four)
return n
print(numbers(1, three=3))what do you expect will be printed? What is actually printed? What rule do you think Python is following?
1234one2three41239SyntaxError
Given that, what does the following piece of code display when run?
a: b: 3 c: 6a: -1 b: 3 c: 6a: -1 b: 2 c: 6a: b: -1 c: 2
Attempting to define the numbers function results in
4. SyntaxError. The defined parameters two and
four are given default values. Because one and
three are not given default values, they are required to be
included as arguments when the function is called and must be placed
before any parameters that have default values in the function
definition.
The given call to func displays
a: -1 b: 2 c: 6. -1 is assigned to the first parameter
a, 2 is assigned to the next parameter b, and
c is not passed a value, so it uses its default value
6.
Key Points
- Define a function using
def function_name(parameter). - The body of a function must be indented.
- Call a function using
function_name(value). - Variables defined within a function can only be seen and used within the body of the function.
- Variables created outside of any function are called global variables.
- Within a function, we can access global variables.
- If we want to do the same calculation on all entries in our columns, we can pass the dataframe columns as the inputs to a function.
- Use
help(thing)to view help for something. - Put docstrings in functions to provide help for that function.
- Specify default values for parameters when defining a function using
name=valuein the parameter list. - Parameters can be passed by matching based on name, by position, or by omitting them (in which case the default value is used).
- Put code whose parameters change frequently in a function, then call it with different parameter values to customize its behavior.